Daily Trend [10-17]
【1】RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
【URL】http://arxiv.org/abs/2307.15818
【Time】2023-07-28
一、研究领域
Robotic Control, Vision-Language Model
二、研究动机
对web-scale数据训练的大型视觉语言模型进行微调,以直接充当可泛化和语义感知的robitic policies
三、方法与技术
(1)预训练VLM:Base Model 是 PaLI-X 和 PaLM-E
(2)将Action离散化为Token,将Robot数据转化为适合VLM模型的数据:方法和RT-1一致
(3)Co-fine-tuning:用 robotics data 和 original web data 共同微调VLM(按比率提高)
(4)实时推理
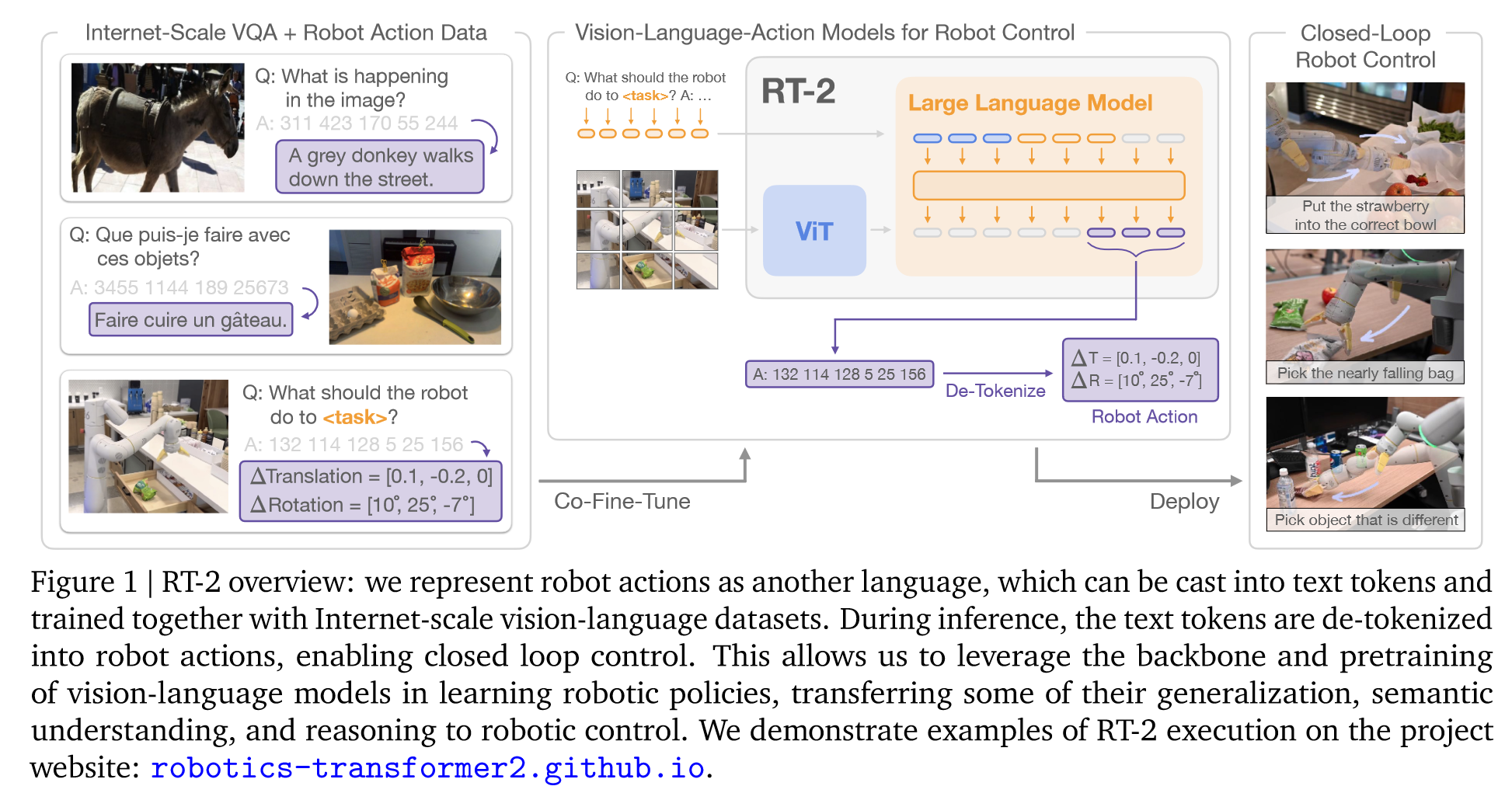
四、总结
最重要的是数据的混合和比例分配
【2】Learning Interactive Real-World Simulators
【URL】http://arxiv.org/abs/2310.06114
【Time】2023-10-09
一、研究领域
World Model, 交互式 Agent, 通用视频生成
二、研究动机
向构建交互式真实世界模拟器迈出第一步
三、方法与技术
(1)数据融合:Simulated execution and renderings, Real robot data, Human activity videos, Panorama scans, Internet text-image data.
(2)训练条件扩散模型:文本和action使用T5转换为连续嵌入,条件是action和先前的噪声观察
(3)定义真实世界为一个POMDP(马尔可夫决策问题):POMDP 可以定义为一个元组 M := ⟨S, A, O, R, T , E⟩,由状态、动作和观察空间以及奖励、转换和观察发射函数组成。 POMDP 可以表征与现实世界的交互。
(4)训练UniSim作为转移函数:Base Model 是Video Diffsion,训练方式是CFG
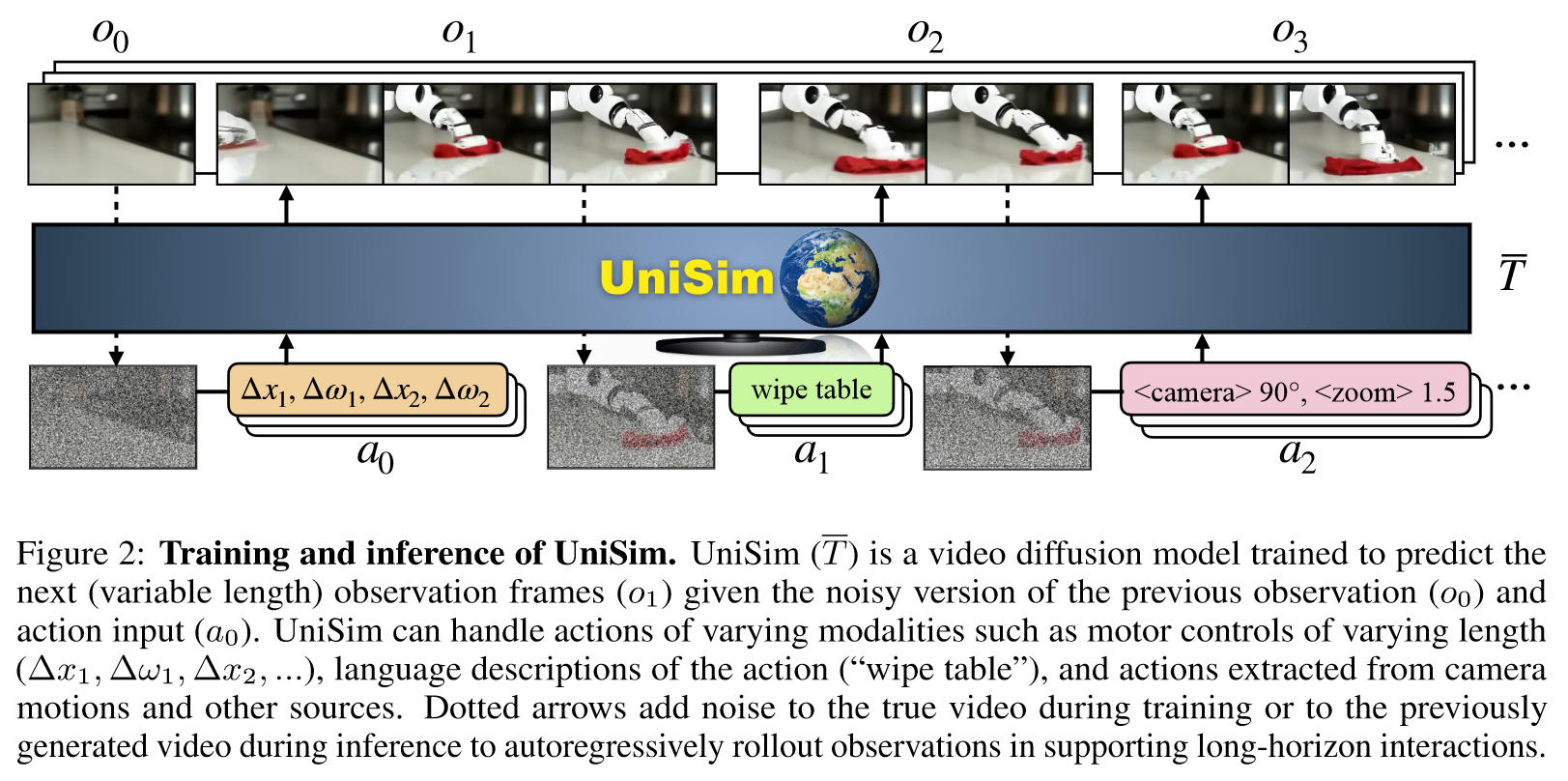
四、总结
交互式现实世界模拟器和典型视频生成模型之间的主要区别在于,模拟器需要支持:
(1)a diverse set of actions
(2)long-horizon rollouts.
UniSim的Demo能力非常强悍:https://universal-simulator.github.io/unisim/
但同时训练所需数据量也非常非常巨大:
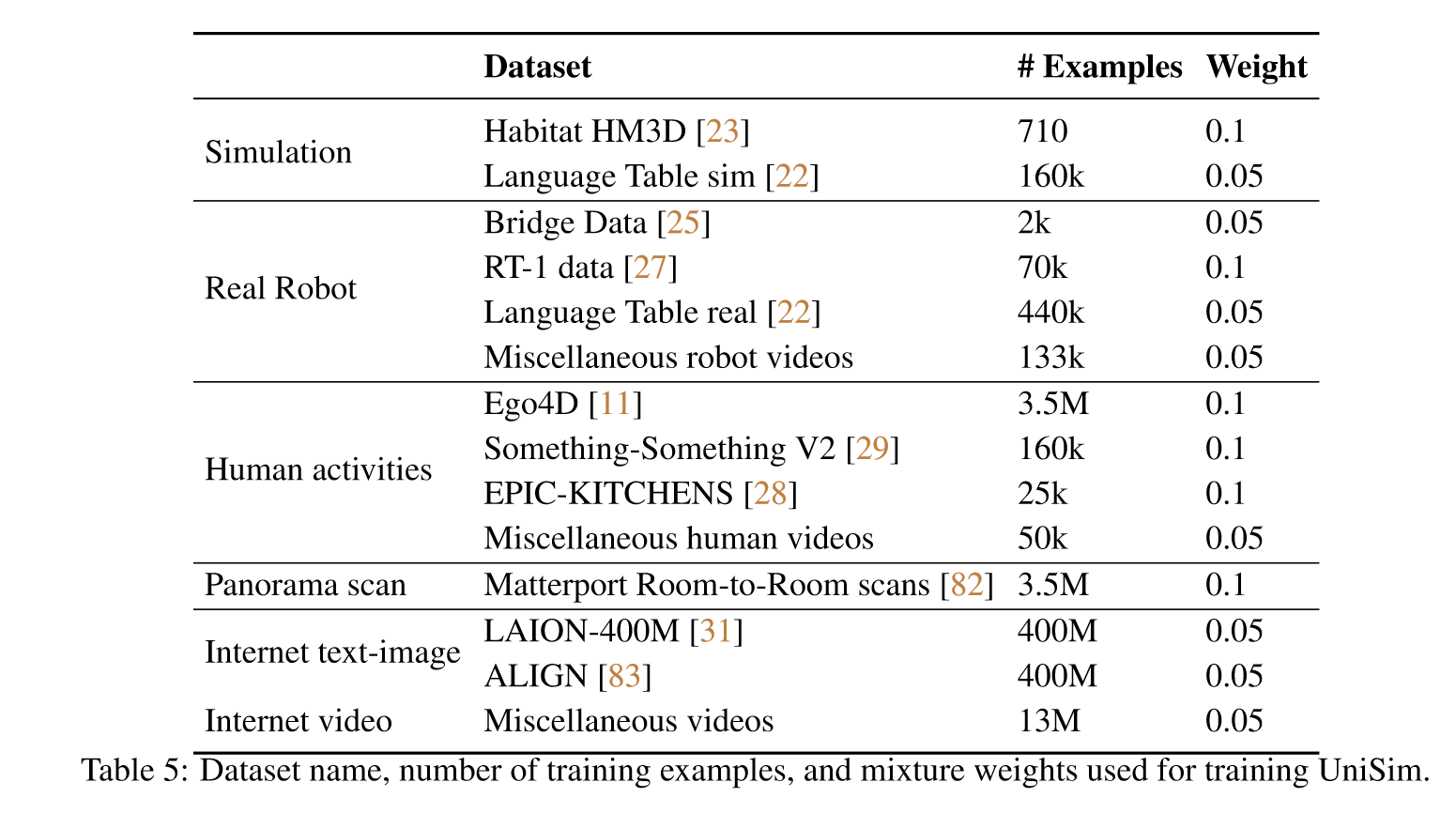
【3】Video Language Planning
【URL】https://openreview.net/forum?id=9pKtcJcMP3
【Time】2023-10-13
一、研究领域
Video Language Planning, Robotic
二、研究动机
基于 VLP 的系统比最先进的替代方案更有可能实现长视野指令的任务完成,包括直接针对长期任务进行微调的方法 PaLM-E 和 RT-2 。
三、方法与技术
(1)使用VLM规划任务
(2)使用启发式算法搜索和约束任务
(3)使用Video作为Dynamics Model预测状态(包括结果状态和中间状态插值)
(4)根据Policies的调整对video做action regression和replanning
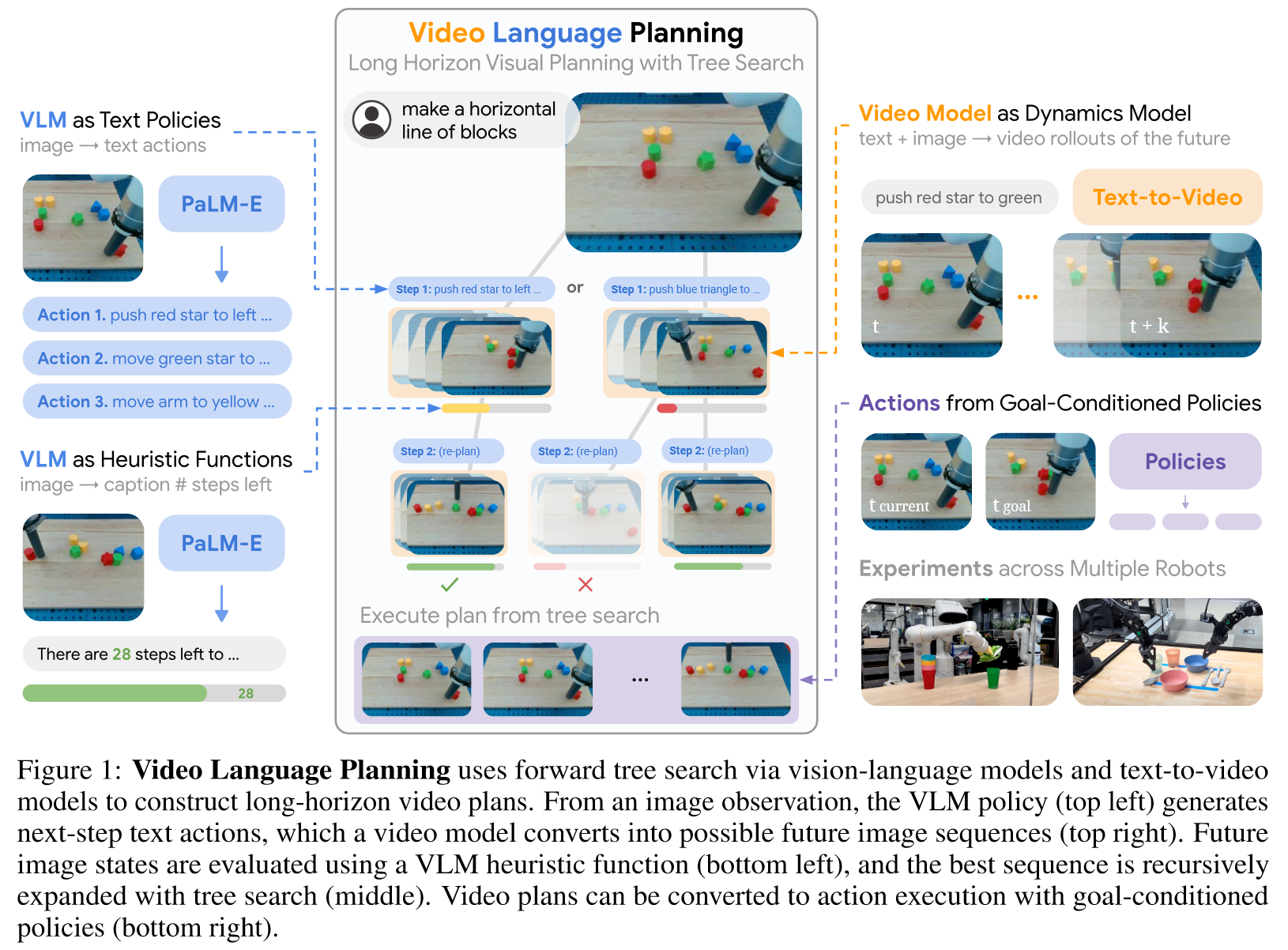
四、总结
Pipeline极其复杂,但任务拆解和规划的思路比较清晰合理
五、推荐相关阅读
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control